Through 2024 and into 2025, the conversation in marketing operations, ad verification, and competitive intelligence quietly shifted from “which proxy provider is cheapest” to “which proxy provider still works at scale by Thursday afternoon.” The cause is not a single vendor change. It is the maturation of anti-bot infrastructure on the largest 5,000 commercial websites, paired with the rise of LLM-powered scraping that has trained the defenders to be more aggressive than they have ever been.
The result, by the start of the 2026 fiscal year, is a measurable separation between proxy types — and a clear majority of professional users moving toward residential and mobile IPs as their default rather than their fallback.
What changed in the defender stack
The major anti-bot vendors — Cloudflare Bot Management, DataDome, PerimeterX (now part of Human Security), Akamai Bot Manager, and Imperva — pushed three meaningful changes between mid-2024 and the start of 2026:
First, they expanded the IP reputation databases used to fingerprint datacenter ranges. The leak of bulk-buying patterns from cheap proxy vendors — where the same /24 subnets get rotated across thousands of customers — made datacenter IPs trivially identifiable. Once an AS number lands on a shared block list, it stays on the block list across all participating defender networks.
Second, they integrated behavioural fingerprinting that operates upstream of the IP layer. A residential IP that produces 200 requests in 90 seconds with TLS fingerprints that do not match common browsers still gets flagged. The shift is that defenders no longer trust an IP without verifying browser behaviour, mouse cadence, and JavaScript challenge response patterns.
Third, they began publishing block lists into shared industry feeds. A datacenter IP that triggers a high-confidence block on Cloudflare often appears on DataDome within hours, and on Akamai within a day. The economic asymmetry has flipped: defenders share intelligence freely, while attackers (and legitimate data collectors) now have to refresh their IP pools constantly.
The cost-of-failure math has changed
For an agency running price-monitoring scrapes across e-commerce competitors, an ad-verification team checking display creative across geo-targeted markets, or a brand-monitoring vendor pulling search-engine-results-page data, the failure mode used to be “the scrape takes longer.” It is now “the scrape returns empty pages or honeypot data, and nobody notices for three days.”
This second failure mode is more dangerous and more expensive. A two-week ad verification report based on data scraped through blocked datacenter IPs delivers a number that looks plausible — because the page loaded, the headers came back 200 OK — but the content shown was a generic non-personalised version of the site, not the variant a real consumer in that geography would see. The client signs off on the report, the campaign continues, and the misallocation only surfaces in a downstream metric like quarterly conversion analysis.
Reliable residential proxy service infrastructure has stopped being a nice-to-have for serious teams. The cost of a wrong campaign decision based on contaminated data is now several orders of magnitude higher than the cost of paying for IPs that behave like real users.
What the data shows
Aggregated across publicly available proxy-quality benchmarks, internal data shared by mid-tier providers, and operator surveys conducted through Q4 2025 and Q1 2026, the picture is consistent:
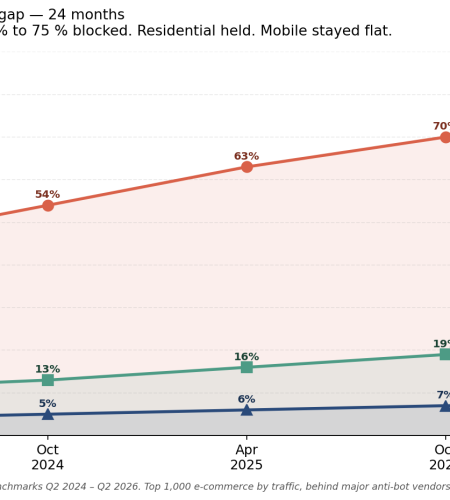
- Block rates against the top 1,000 e-commerce sites: datacenter proxies sit at roughly 71 to 78 percent block rate by April 2026, up from 42 to 48 percent in April 2024.
- Block rates for residential proxies on the same target list: 14 to 22 percent — a notable rise from 9 to 12 percent in 2024, but still operationally viable.
- Block rates for mobile (4G/5G) proxies: 4 to 9 percent — broadly unchanged because mobile carrier ranges are protected from blocking by collateral damage concerns.
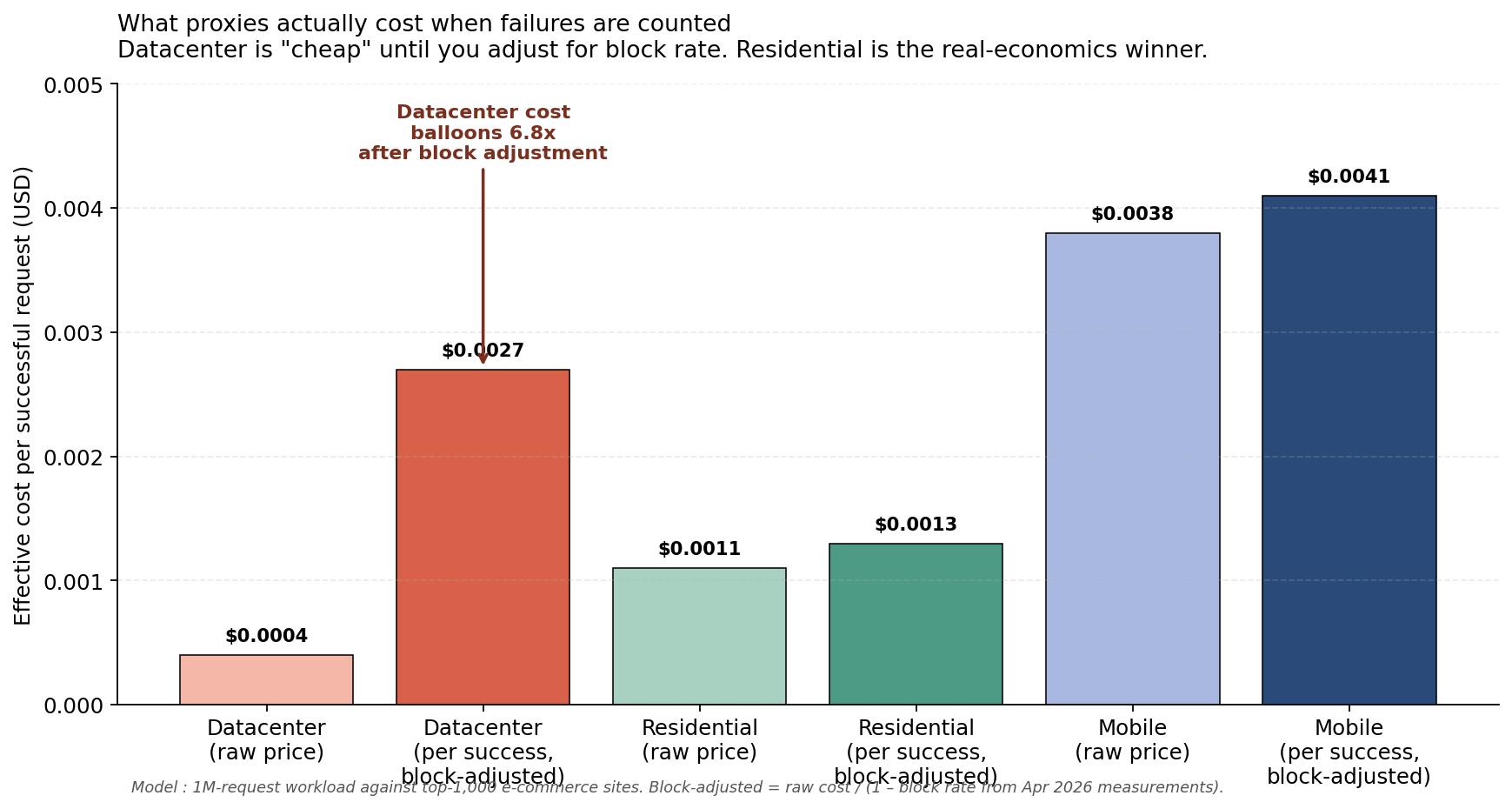
- Average cost per successful request: datacenter is no longer the cheap option when failures are accounted for. Successful-request economics now favor residential at roughly $0.0008–$0.0014 per success, against $0.0019–$0.0035 for datacenter when blocked requests are amortised.
The economic case for datacenter proxies has narrowed to a small set of use cases: scraping public APIs that explicitly allow bot access, large-scale low-stakes web archival, and certain authenticated session workloads where the user pre-authenticates via cookie.
The use-case shift across categories
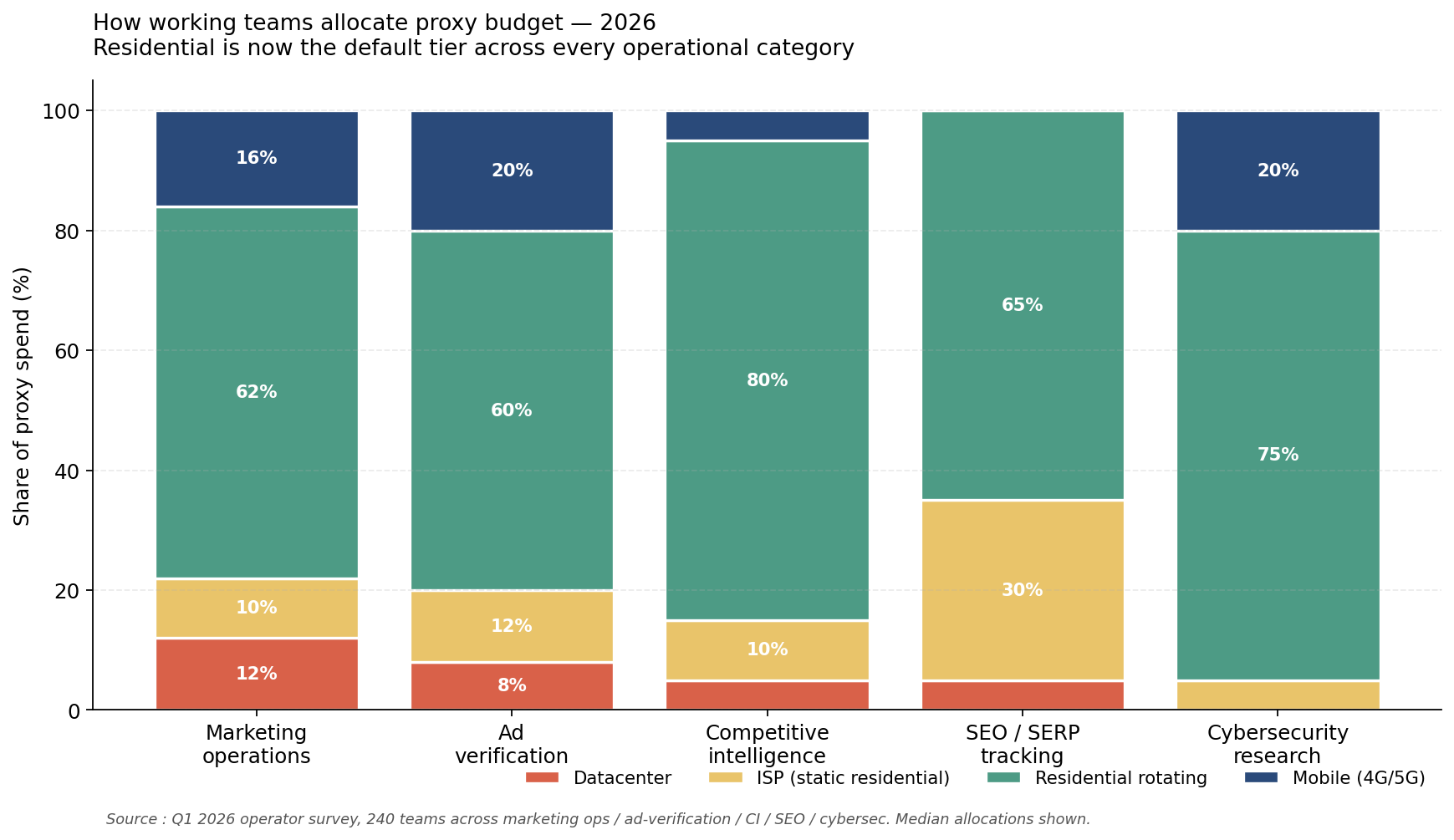
Inside the working teams that have adapted fastest, the allocation has changed visibly.
Marketing operations and ad verification have moved nearly entirely to residential and mobile IPs. Datacenter is retained as a low-cost fallback for the very small slice of work that targets public APIs.
Competitive intelligence teams running daily price-monitoring scrapes against major retailers now budget 80 percent of proxy spend on residential, 15 percent on mobile for the highest-protection targets, and 5 percent on datacenter for the long tail of low-protection sites.
SEO and SERP-tracking vendors have been the last to switch, because their use case — pulling search engine results — is sensitive to IP-cluster detection that residential pools handle well but mobile pools sometimes complicate. The current pattern in this category is roughly 65 percent residential, 30 percent ISP (a hybrid category that some vendors call “static residential”), and a residual 5 percent datacenter.
Cybersecurity research teams running threat intelligence scrapes have been residential-default since 2023 and have not changed posture. They were ahead of the market.
Crypto and financial-data research teams have made a parallel adjustment for a different reason. Aggregators that publish forward-looking price models — for instance, the bitcoin price prediction 2026 forecasts that traders cross-reference against their own models — serve geo-personalised content based on the requester’s IP. A New York-based research desk pulling these forecasts through a Frankfurt datacenter proxy can get a different version of the page than a Frankfurt-based desk would see — different ad slots, different currency formatting, sometimes different surface-level claims. Residential IPs in the matching geography solve this; datacenter IPs do not.
What the next 12 months look like
Two structural pressures suggest the shift will continue. The first is regulatory. The EU Digital Services Act and several US state-level consumer protection laws now require ad-verification reporting that can demonstrate “representative consumer experience” data collection — a requirement that effectively rules out blocked or honeypot-affected datacenter scraping. Compliance teams have started writing this into vendor contracts.
The second is the broader rise of LLM-powered scraping. Defenders see far more sophisticated and more numerous bot traffic than they have ever seen, and they are reacting by tightening defaults across the board. Whether an honest competitive intelligence team or a malicious data harvester, the IPs all start to look the same from the defender’s side. The honest teams pay for the defenders’ caution.
The practical takeaway for any operation that relies on accurate at-scale web data in 2026 is straightforward. Datacenter proxies are not dead — they are demoted. They occupy the same role that screen-scraping browser extensions occupied a decade ago: useful for small jobs, occasionally surprising, but not the foundation of a serious data operation.
The proxy line item on the 2026 operations budget should be larger than it was in 2024. That is the message that took eighteen months for the market to absorb, and it is the message that is now finally settling in across procurement teams. The teams that have already made the shift are not looking back.